Map4RDF
Recientemente, hemos visto un gran incremento en la cantidad de datos geoespaciales que están publicados
utilizando RDF y los principios de Linked Data.
Esfuerzos como el W3C Geo XG, y más recientemente la iniciativa
GeoSPARQL están proporcionando los vocabularios necesarios para publicar este tipo de información en la Web de Datos.
map4rdf es un herramienta para explorar y visualizar conjuntos de datos RDF enriquecidos con información geométrica.
map4rdf es un software open source. Sólo configuralo para usar tu SPARQL endpoint y proporciona a tus usuarios
con una buen visualización en un mapa de tus datos. Los aspectos geoespaciales de los datos se pueden modelar
usando o el modelo de datos del W3C Geo XG o el modelo de datos propuesto por GeoLinked Data (.es).
Para descargarlo, utilice el siguiente enlace.
Puede acceder a una demo en la siguiente dirección (utilizando un endpoint de GeoLinkedData).
Puede acceder a una demo en la siguiente dirección (utilizando un endpoint de DBpedia).
Acerca de map4rdf:
- Interfaz de exploración facetada
- Visualizacion geoespacial mediante Google Maps.
- Visualización de geometría (LineStrings, Polygons, etc) cuando se utiliza el modelo GeoLinkedData.
- Visualización de datos estadísticos utilizando SCOVO
Para consultar la información completa de map4rdf (instalación, configuración y uso), visite la página oficial
en el siguiente enlace.
Virtuoso
Virtuoso es un servidor de datos multimodelo para las iniciativas ágiles e individuales.
Ofrece una solución independiente de plataforma sin rival para la gestión de datos, acceso e integración.
La arquitectura única del servidor híbrido de Virtuoso le permite ofrecer la funcionalidad del servidor
tradicional dentro de una oferta de producto única que cubre las siguientes áreas:
- Gestión de Datos Relacionales
- Gestión de Datos RDF
- Gestión de datos XML
- Gestión de Contenidos de texto libre y de indexación completa de texto"Documento de servidor Web
- Servidor de Linked Data
- Servidor de aplicaciones web
Pubby
Pubby se puede utilizar para añadir interfaces de Linked Data a SPARQL endpoints.
Gran parte de los datos de la Web Semántica reside dentro de las triples stores y sólo se puede acceder
mediante el envío de consultas SPARQL a un SPARQL endpoint. Es difícil conectar la información en estas triples
stores con otras fuentes de datos externas.
Pubby hace que sea fácil convertir un SPARQL endpoint en un servidor de Linked Data. Se
implementa como una aplicación web en Java.
Silk
Silk es una herramienta que sirve para encontrar relaciones entre recursos
pertenecientes a distintas fuentes de Linked Data.
Los creadores de nuevas colecciones pueden utilizar esta herramienta para unir sus enlaces RDF de sus fuentes de datos con
otras fuentes de la Web.
The Silk framework is a tool for discovering relationships between data items within different Linked Data sources.
Data publishers can use Silk to set RDF links from their data sources to other data sources on the Web.
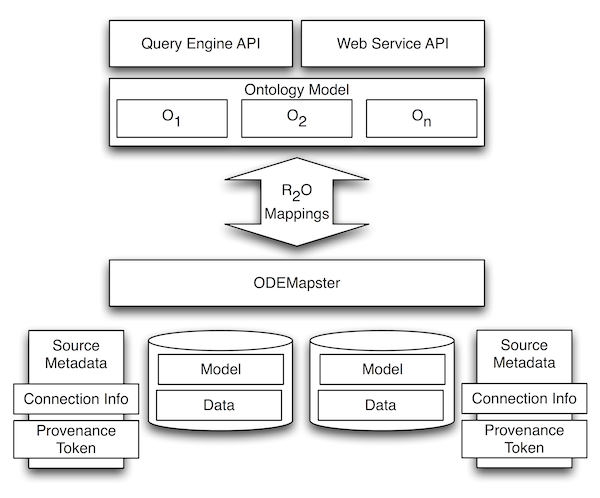
R2O & ODEMapster
R2O & ODEMapster es un marco integrado para la expresión formal, la evaluación, verificación y explotación de correspondencias semánticas
entre ontologías y bases de datos relacionales. El marco integrado está compuesto por:
 R2O, un lenguaje formal declarativo con expresividad suficiente como para representar situaciones de correspondencia complejas debidas
al hecho de que se alinean dos modelos desarrollados y mantenidos de forma independiente y entre los que pueden darse disparidades de todo tipo.
R2O, un lenguaje formal declarativo con expresividad suficiente como para representar situaciones de correspondencia complejas debidas
al hecho de que se alinean dos modelos desarrollados y mantenidos de forma independiente y entre los que pueden darse disparidades de todo tipo.
 ODEMapster, procesador que se encarga del proceso de upgrade o enriquecimiento semántico del contenido de la base de datos o mediante la extracción
bajo demanda del contenido de la base de datos en respuesta a preguntas planteadas en términos de la ontología mediante un proceso de re-escritura de consultas.
ODEMapster, procesador que se encarga del proceso de upgrade o enriquecimiento semántico del contenido de la base de datos o mediante la extracción
bajo demanda del contenido de la base de datos en respuesta a preguntas planteadas en términos de la ontología mediante un proceso de re-escritura de consultas.
|

